
Every researcher and consultant who conducts interviews makes a promise. Sometimes it is written into an ethics application. Sometimes it is stated in the consent form the participant signs before the recording starts. Sometimes it is simply said out loud at the start of the call: "This will be anonymised before anyone else sees it." Or at minimum it's an unspoken expectation that the discussion can be had in confidence.
That promise is easy to make and surprisingly hard to keep.
Manual anonymisation is slow, inconsistent, and easy to get wrong. A researcher reading through a 60-minute transcript will catch most obvious names, but will often miss the regional office someone mentioned, the unusual job title that points to a single person, or the combination of minor details that together make a participant identifiable even without a name. Run this across a corpus of 30 transcripts and the inconsistencies multiply. Different team members remove different things and the same person is pseudonymised differently across files making it hard to put the full picture together.
Find-and-replace is worse. It catches exact strings and misses everything else: nicknames, pronouns, contextual references, and anything expressed differently across files. Or anything with a typo. And you can be sure that when the report contains the quote "Olly is a bit of a pain in the ***", Olli will not find it amusing...
Asking a general-purpose AI to "remove names and identifying information" sounds promising, but still not good enough for serious research as there is no audit trail, no re-identification key nor consistent treatment of indirect identifiers across a document set. There is no way to demonstrate to an ethics board, a GDPR compliance officer, or an IRB that the process was rigorous.
Skimle Anonymise was built to close this gap. It is a purpose-built workspace for pseudonymising and anonymising qualitative research data: transcripts, reports, interview notes, and any other text documents containing sensitive participant information. It combines AI-powered identifier detection with structured transformation rules, cross-file consistency, and a complete export package that includes an audit report documenting every decision made.
Effortless anonymisation allows you to put your data into use: share interview transcripts or customer feedback with external consultants, bring anonymised material into an internal workshop, or hand off a full corpus to a junior analyst team without worrying about what is in there.
This article explains how Skimle Anonymise works, what the different protection levels mean in practice, and who it is designed for.
Why anonymisation matters more than many realise
Anonymisation and pseudonymisation are not the same thing, and the distinction matters legally and ethically.
Pseudonymisation replaces direct identifiers (names, email addresses, phone numbers) with stand-ins, but a re-identification key is retained somewhere. The data remains personal data under GDPR because re-identification is possible with the key. Pseudonymised data still requires lawful processing grounds, data subject rights apply, and the key itself must be stored securely.
Anonymisation goes further. When done properly, re-identification is not reasonably possible even with the key, because the key has been destroyed and the data has been transformed sufficiently to prevent any plausible inference of identity. Truly anonymised data falls outside GDPR's scope entirely.
The ICO's guidance on anonymisation and pseudonymisation makes clear that many researchers who believe they have anonymised data have actually only pseudonymised it, and that even pseudonymisation requires careful thought about indirect identifiers: the job title, the location, the specific incident described, the combination of demographic details that narrows a population to one person.
For researchers, this matters in two directions: It matters for protecting participants, which is the ethical obligation. And it matters for compliance, because GDPR and HIPAA impose legal obligations that do not disappear just because the direct name has been removed.
After dealing with the pain of anonymising and pseudonymising data across academic and business settings for decades, we decided to add this feature to Skimle and to do it properly. Hence announcing Skimle Anonymise.
How Skimle Anonymise works
Uploading and detection
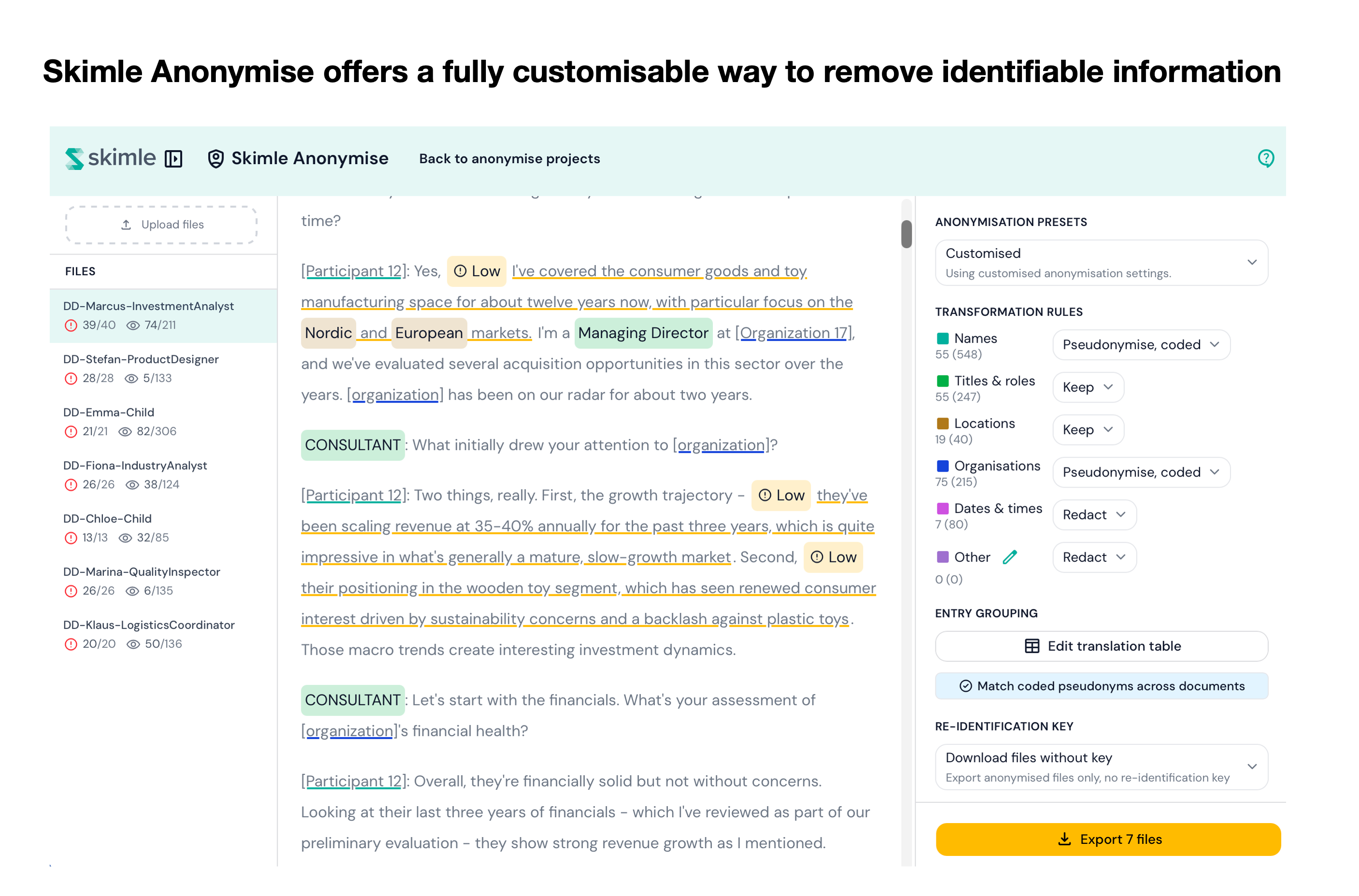
The process starts by uploading transcripts, interview notes, reports, or any other text documents into a Skimle Anonymise project. You can upload multiple files at once, and the tool treats them as a unified corpus.
Once uploaded, the AI scans every document for identifiers across six categories:
- Names: personal names of participants, third parties, family members, colleagues
- Titles and roles: job titles, seniority levels, professional designations, role descriptions specific enough to identify a person
- Locations: addresses, named offices, cities, regions, or any geographic detail that could narrow identity
- Organisations: company names, departments, divisions, institutions, and named teams
- Dates and times: specific dates, meeting times, employment dates, or temporal references that could pin events to individuals
- Other: anything not captured above, including identifiers the AI recognises as contextually sensitive
Each detected instance is highlighted in the document view, categorised, and listed in a structured panel alongside the document. The AI works across all files simultaneously, so it can identify when the same entity appears across multiple documents and flag cross-file consistency issues from the start.
This is where most manual processes and general-purpose AI tools fail. They handle files one at a time, which means the same person might be given different pseudonyms in different documents, destroying the analytical coherence of the dataset. Skimle Anonymise maintains a shared entity registry across the entire project.
Protection levels
Rather than asking researchers to configure every setting from scratch, Skimle Anonymise offers three preset protection levels that map to common research scenarios.
Level 1 (light pseudonymisation) targets direct identifiers only. Names are replaced with consistent pseudonyms, contact details are removed or replaced, and other obvious direct identifiers are transformed. The re-identification key is retained. This level is appropriate when you need to share transcripts within a project team while protecting participant identity from casual exposure, but where re-identification might still be needed for follow-up research. Legally, the data remains personal data under GDPR.
Level 2 (strong pseudonymisation) extends the treatment to indirect identifiers: unusual job titles, specific locations, organisational details, and dates that could contribute to re-identification. The re-identification key is still retained. This is the appropriate level for most shared research data in academic and corporate settings, where participants have been promised anonymity but the research team still needs audit capability.
Level 3 (full anonymisation) applies the most aggressive transformation: all categories are processed, indirect identifiers are either transformed or suppressed, and the re-identification key is permanently destroyed upon export. Once the key is destroyed, re-identification is not technically feasible from the data alone. The project is archived. This level is designed for HIPAA-covered research, the highest-risk academic contexts, and any scenario where participants have been promised full anonymisation and the researcher must be able to demonstrate it. It is irreversible by design, assuming you delete the source data from all your own devices.
Researchers can start at Level 1 and work progressively toward higher protection, using the structured review process to check each transformation before committing to a higher level.
Per-category transformation modes
Beyond the preset levels, each identifier category can be configured with its own transformation mode. This gives researchers control over how different types of information are handled, rather than applying a single rule to everything.
The available modes are:
- Keep: leave the identifier unchanged (used for identifiers the researcher has determined are safe to retain)
- Pseudonymise: replace with a consistent stand-in (Person A, Site 3, Organisation B), with the mapping recorded in the re-identification key
- Neutralise: remove the identifier and replace with a generic placeholder ("[name]", "[organisation]")
- Generalise: replace a specific identifier with a broader category ("London" becomes "major UK city", "Head of EMEA Sales" becomes "senior sales leader")
- Approximate: apply controlled distortion ("25 March 2024" becomes "late March 2024", a specific age becomes an age band)
- Redact: remove entirely with no replacement
Different categories often call for different modes. Names are typically pseudonymised rather than redacted, so the text remains readable and the analytical relationship between quotes is preserved. Specific locations might be generalised. Exact dates might be approximated. The mode configuration lets researchers make these decisions category by category, rather than applying a one-size-fits-all rule.
Cross-file consistency
This is one of the most practically important features. When the same person appears in multiple documents under different names or descriptions, Skimle Anonymise's entity registry keeps track and assigns the same pseudonym consistently.
If "James" in one transcript is the same person as "Jim in the Edinburgh office" in another, you can merge those into a single entity. After merging, both references are pseudonymised identically across all documents, so the analytical coherence of the dataset is preserved. Any downstream analysis, whether in Skimle or in another tool, will correctly recognise that the same person is being quoted.
This matters enormously for qualitative analysis. If a researcher is trying to analyse interview transcripts to understand how different stakeholders relate to each other, inconsistent pseudonymisation destroys that picture.
Custom redaction rules
Not all identifying information falls neatly into predefined categories. A dataset might contain product codenames used only within one organisation, a distinctive phrase that only one person in the study uses, or references to a named internal programme that would immediately identify the organisation.
Custom redaction rules let researchers specify these in plain language: "Remove all references to Project Athena", "Replace all uses of the phrase 'our Birmingham pilot' with 'a regional pilot'", "Remove all gendered pronouns throughout". The AI applies these rules consistently across all documents, treating them as first-class transformation instructions alongside the category-level configuration.
Risk detection
After the AI has applied transformations, it does a second pass to identify passages that may still carry re-identification risk even after the primary transformation. This is particularly important for Level 2 and Level 3 scenarios, where indirect identifiers in combination can still point to specific individuals even after obvious direct identifiers have been removed.
Flagged passages are surfaced for human review with an explanation of why the AI considers them higher risk. The researcher can then decide whether to apply additional transformation, manually edit the passage, or accept the risk with a documented rationale. This review step is part of what makes the process auditable.
Risk detection addresses one of the core weaknesses of manual anonymisation: the difficulty of recognising when a combination of details is identifying even though each detail in isolation would not be. A passage mentioning "a former Partner at McKinsey who spent 18 years in the Helsinki office before joining Skimle as co-founder" might contain no direct names, but it would still describe exactly one person.
Re-identification key management
At export time, researchers have three options for the re-identification key:
- Download with key: the export package includes the full translation table mapping every pseudonym to the original identifier. This is needed when re-identification might be required later, for example for follow-up interviews or data correction.
- Download without key: the anonymised documents are exported but the key is not included in the package, even though it still exists in the project. This is useful for sharing anonymised data with collaborators who should not have access to the key.
- Destroy key permanently: the key is deleted from all systems and cannot be recovered. This is the final step for Level 3 anonymisation. The project is archived in a read-only state.
This three-way structure reflects the genuine variety of research situations. Some projects need key access to remain possible. Some need the key to exist but be held separately. Some require demonstrable, irreversible key destruction.
The export package
When a project is ready for export, Skimle Anonymise produces a package containing three elements:
Anonymised documents (in Word format): the full set of transformed documents, formatted for readability. Each document has a filename that corresponds to the original, making it easy to track provenance without re-identifying.
PDF audit report: a complete record of every transformation applied across the project: which identifiers were detected, what category each fell into, what transformation mode was applied, and any manual overrides made by the researcher. The audit report is the artefact that demonstrates to an ethics board, IRB, or compliance officer that the anonymisation process was rigorous and systematic. It is signed with a timestamp.
Excel translation table: the full re-identification key in structured tabular format, listing every entity and its pseudonym. This file is only included when the researcher has chosen to download with the key.
For researchers working in academic contexts where thematic analysis or other systematic methods will be applied to the anonymised data, the DOCX files feed directly into Skimle's analysis workflow. There is no intermediate step.

Who this is for
Academic researchers
Academic researchers operate under the most stringent requirements. Ethics committees expect not just a promise of anonymisation but a documented, demonstrable process. The audit report produced by Skimle Anonymise is designed specifically for this context: it provides the evidence trail that a written policy cannot.
For PhD students and early-career researchers managing large interview corpora on limited budgets, the practical dimension matters as well. Our guide on qualitative research for academic researchers covers the broader picture of AI in academic qualitative work, and anonymisation is one of the most time-consuming steps that AI can now handle rigorously.
Skimle's academic research features go beyond anonymisation, but anonymisation is often where the workflow begins.
HR professionals and consultants
In business settings, the requirement is often less formal but no less real. Employees who participate in engagement surveys, exit interviews, or organisational reviews need to trust that their candid responses will not be traceable back to them.
HR teams and consultants conducting these projects often share transcripts across internal teams and external stakeholders. Without proper de-identification, there is real risk of participants being identifiable to managers, colleagues, or clients, which both damages trust and creates compliance exposure under GDPR.
The practical setup for transcription and analysis typically ends with a pile of transcripts that need de-identifying before analysis can be shared. Skimle Anonymise inserts cleanly into that workflow, sitting between the transcription stage and the analysis stage.
For researchers running large projects where how to analyse interview transcripts is the next step, having properly masked and pseudonymised source data matters for both compliance and analytical integrity.
Market researchers and consultants
Commercial research involving customer interviews, expert network calls, or stakeholder consultations often involves information that is commercially sensitive as well as personally identifying. A participant might reveal views about competitors, internal company strategy, or regulatory concerns that they would not want attributed to them.
Pseudonymisation in commercial research is both an ethical obligation to the participant and a practical protection for the researcher. A client who receives an AI qualitative data analysis deliverable wants to know that the underlying data was handled rigorously, and a documented anonymisation process is part of that assurance.
The two-way transparency that Skimle is built on extends to the anonymisation process: the audit report shows exactly what was done and when, making the process explainable to clients and reviewers alike.
Anonymise versus the alternatives
The comparison to manual anonymisation is clear enough: Skimle Anonymise is faster, more consistent, covers more identifier types, and produces an audit trail that manual processes cannot match.
The comparison to general-purpose AI tools is worth being explicit about. A researcher who uploads a transcript to ChatGPT and asks it to "remove names and identifying information" will get something that looks anonymised. But there is no re-identification key management, no cross-file consistency, no structured transformation modes, no risk detection, no audit report, and no way to configure different rules for different identifier types. The result is not verifiably rigorous in the way that ethics boards and compliance frameworks now expect.
Purpose-built tools for specific research tasks consistently outperform general-purpose tools when rigour, auditability, and reproducibility matter. This is a point we have made before in the context of AI text analysis tools, and it applies equally to anonymisation.
Skimle Anonymise is free to test and included in all Skimle packages. Try it on your own data and see how much faster and more rigorous your anonymisation workflow can be.
Want to understand the full research workflow? Read our guide on how Skimle works, explore the academic research use case, or start with our AI qualitative data analysis checklist to make sure your process is sound end to end.
About the authors
Henri Schildt is Professor of Strategy at Aalto University School of Business and co-founder of Skimle. He has published over a dozen peer-reviewed articles using qualitative methods, including work in Academy of Management Journal, Organisation Science, and Strategic Management Journal. His research focuses on organisational strategy, innovation, and qualitative methodology. Google Scholar profile
Olli Salo is a former Partner at McKinsey & Company where he spent 18 years helping clients understand their markets and themselves, develop winning strategies, and improve their operating models. He has conducted over 1000 client interviews and published over 10 articles on McKinsey.com and beyond. LinkedIn profile